Dans un monde où les systèmes d’informations deviennent de plus en plus grands et complexes, il devient difficile de détecter les problèmes rapidement. Splunk permet d’agréger toutes les données issues de votre système d’information (réseau, serveurs, applications, sites web, machines virtuelles …) en un seul et unique endroit.
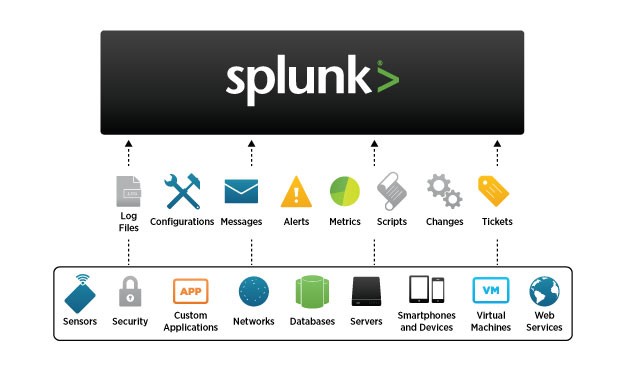
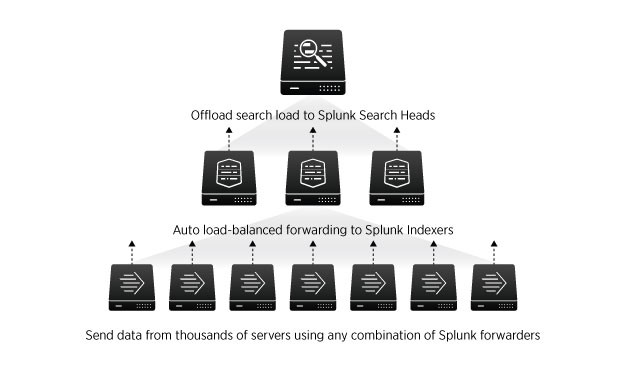
Le recueil des données se fait via une application développée spécialement pour cette tâche par les équipes de Splunk. On l’appelle le forwarder. Il va collecter en temps réel et de manières sécurisées les données et les transférer à l’instance principale de splunk qui se charge de l’indexation. Leur administration est gérée de manière centralisée. Ils sont capables de surveiller les modifications sur des fichiers (ex : les fichiers de log, de configuration), de récupérer le résultat de commandes (ex : SNMP).
L’architecture de splunk entreprise est robuste, elle peut évoluer pour recueillir des centaines de téraoctets par jour et assure une continuité de service grâce à des technologies de clustering. Le clustering peut se faire sur du multisite pour que vos données soient répliquées.
Toutes les données remontées dans splunk sont ensuite exploitées au travers de rapports, tableaux de bord ou encore alertes. Ils permettent la transformation de données brutes en graphiques lisibles et compréhensibles par tous. Mais, toutes les données ne sont pas accessibles pour tous. La sécurisation de l’accès aux données est basée sur les rôles. Ainsi, tout le monde ne peut accéder aux données des machines sensibles. Les rôles des utilisateurs et les fonctionnalités associées peuvent être facilement intégré dans un annuaire LDAP (ex : Active Directory).
Ci-dessous, un exemple de tableau de bord :
Et pour finir, une petite vidéo qui présente Splunk :




